
If you've ever dealt with database records or system events, you know how critical a unique identifier is. A UUID GUID generator is the tool that creates these identifiers—a 128-bit number that guarantees every single record can be tracked without ever overlapping. For developers, this is a huge relief. It means you can stop worrying about duplicate primary keys, especially in complex, distributed systems where keeping things in sync is a nightmare.
Understanding UUIDs and Why They're a Developer's Best Friend
At its heart, a Universally Unique Identifier (UUID)—or what Microsoft calls a Globally Unique Identifier (GUID)—is a standardized 128-bit number engineered to be unique across any system, anywhere in the world. Think of it as a digital fingerprint for your data.
It’s a far cry from a simple auto-incrementing integer (1, 2, 3). A UUID, which looks something like f81d4fae-7dec-11d0-a765-00a0c91e6bf6, can be generated on any machine, at any time, without needing a central system to approve it. This ability to work independently is exactly why UUIDs have become so essential in modern software development.
Solving Problems in the Trenches
Let's get practical. Imagine you’re building an app with a microservices architecture. A single user request might bounce between five different services to get the job done. How do you possibly trace its path? You assign a UUID as a correlation ID the moment the request comes in. By tagging every log and event with that same ID, you can easily piece together the entire journey, which makes debugging a lifesaver.
Here are a few other real-world spots where a UUID is the perfect solution:
- Distributed Databases: If you're running database instances across multiple regions, sequential IDs are a recipe for failure. It's almost guaranteed that two servers will try to create a record with
ID: 101at the same time, causing a nasty data collision. UUIDs let each instance generate its own globally unique keys without stepping on any toes. - API Idempotency: To stop a user from accidentally placing duplicate orders because of a flaky network connection, you can ask for an idempotency key with the API request. This key is often a UUID generated on the client's side. The server can then see the key, recognize it's a duplicate request, and safely ignore it.
- Offline-First Applications: For apps that need to work without a steady internet connection, users will inevitably create data while offline. A
uuid guid generatorcan create unique IDs for that new data right on the device. Once the app is back online, it can sync everything up with the server without any ID conflicts.
The Near-Impossible Chance of a Collision
The math behind UUID uniqueness is just mind-boggling. For Version 4 UUIDs, which are the most common random ones, 122 of the 128 bits are purely for randomness. This gives you a pool of over 5.3 undecillion possible combinations.
To put that into perspective, the probability of a duplicate is so ridiculously low that if you generated one billion UUIDs every second for a year, you’d only have a 50% chance of a single collision. You can dig into the specifics of the standard that makes this possible on Wikipedia's UUID page.
This statistical guarantee is a massive win for developers. It means you can generate IDs with confidence anywhere in your stack—on the client, on the server, in a serverless function—and trust they're unique without a round trip to a central database. That's the key to building systems that are scalable, resilient, and loosely coupled.
Picking the Right UUID Version for Your Project
Choosing a UUID version is more than just a technical detail; it’s a foundational decision that can affect your database performance, system security, and even data privacy down the line. It's easy to just grab the default from a generator, but taking a moment to understand the differences will pay off massively.
This flowchart gives you a quick mental model for when UUIDs are the right tool for the job.
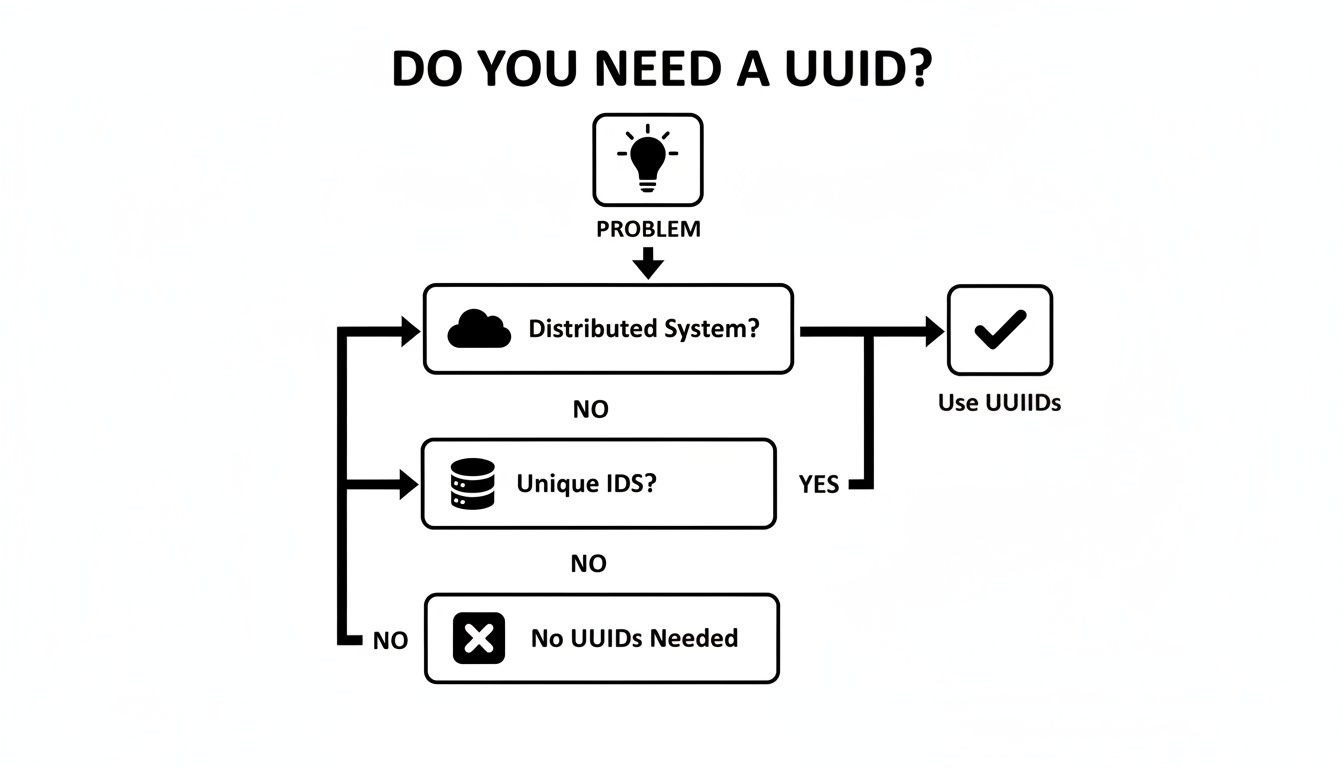
If you've landed here, you probably need a unique ID for a distributed system. Now, the real question is: which kind of UUID do you need?
UUID Version Comparison for Developers
To make this decision easier, I've put together a quick-reference table that boils down the key differences between the most common UUID versions. Think of it as a cheat sheet for your next project.
| UUID Version | Generation Method | Uniqueness Guarantee | Privacy/Security Risk | Common Use Case |
|---|---|---|---|---|
| Version 1 | Timestamp + MAC Address | High, but not guaranteed across all systems if clock is reset. | High: Leaks MAC address and creation time. | Event logging, time-series data where chronological sorting is a priority and privacy is not a concern. |
| Version 3 | Namespace + Name (MD5 hash) | Deterministic; same inputs produce the same UUID. | Medium: MD5 is vulnerable to collisions. | Legacy systems requiring deterministic IDs. Avoid for new projects. |
| Version 4 | Cryptographically Secure Random Numbers | Extremely High: Collisions are statistically impossible. | Low: Contains no identifiable information. | The default choice for most modern applications: database primary keys, API keys, transaction IDs. |
| Version 5 | Namespace + Name (SHA-1 hash) | Deterministic; same inputs produce the same UUID. | Low: SHA-1 is more secure than MD5. | Generating stable, repeatable IDs from a known string (e.g., a user ID from an email address). |
This table covers the high-level trade-offs, but let's dig into the practical implications of each.
Version 4: The Random, Secure Default
For probably 95% of use cases today, Version 4 (V4) UUIDs are what you want. They are generated from truly random (or, more accurately, pseudorandom) numbers, which makes the chance of two being the same astronomically low. We're talking lottery-winning-level odds.
The biggest win here is security through obscurity. A V4 UUID contains zero information about when or where it was created. This makes it a perfect fit for things like:
- Unique IDs for new database records (primary keys).
- Tracking requests or operations (transaction IDs).
- Ensuring an API request is processed only once (idempotency keys).
The only real catch? Their pure randomness can sometimes work against you in certain database setups. If your database uses clustered indexes (like some SQL databases do by default), inserting random V4 UUIDs can cause index fragmentation, leading to slightly slower writes over time as the database has to slot new records into random spots.
Version 1: Time-Based but Risky
A Version 1 (V1) UUID is created from a timestamp and the MAC address of the computer that generated it. This gives it a unique property: it’s time-sortable.
Because V1 UUIDs are generated in a roughly sequential order, they play much nicer with clustered indexes, often resulting in better write performance for databases. They're a solid choice for things like event logging systems where keeping records in chronological order is a core requirement.
Here’s the massive caveat: V1 UUIDs are a privacy nightmare. They broadcast the exact time of creation and the unique MAC address of the generating machine. This is a significant information leak that can be a security vulnerability, making them completely unsuitable for any public-facing or security-conscious application.
Versions 3 and 5: Name-Based and Deterministic
What if you don't want a random ID? Sometimes, you need to generate the exact same ID for the same piece of data, every single time. That’s the job of name-based UUIDs.
Both Version 3 (which uses an MD5 hash) and Version 5 (using a more secure SHA-1 hash) create a deterministic UUID. You provide two things: a namespace (another UUID that acts as a context, like my-app-users) and a name (a string you want to identify, like an email address). The generator then produces a UUID that is always the same for that specific namespace/name pair.
This is incredibly useful when you need to create a stable identifier from a known piece of information, like creating a consistent user ID from their email.
Because the MD5 algorithm is considered cryptographically broken, you should always choose Version 5 for any new development. If you want to see how this deterministic generation works in practice, you can get UUIDs online and explore the methods behind them.
So, the choice comes down to your needs: V4 for randomness, V1 for time-sorting (if you can live with the risk), and V5 for repeatable, deterministic IDs.
Generating Secure UUIDs in JavaScript and Node.js
Alright, let's get our hands dirty and move from theory to actual code. Generating secure UUIDs in JavaScript, whether you're in the browser or a Node.js environment, is pretty straightforward once you know which tools to reach for. The absolute key is to use cryptographically secure APIs. If you skip this, you risk creating identifiers that aren't truly random, which can open up some nasty, subtle security holes.
We'll walk through the go-to methods for creating both Version 4 (random) and Version 5 (deterministic) UUIDs that you can drop right into your projects.
On the Client-Side: Using the Browser's Crypto API
Every modern browser comes equipped with the crypto object, which is your direct line to a cryptographically strong random number generator. This is the only source you should trust for creating secure V4 UUIDs on the front end. I can't stress this enough: stay away from Math.random() for anything security-related. It's just not built for it.
The function we need is crypto.getRandomValues(). It fills an array with truly random numbers, which we can then massage into the standard UUID format.
Here’s a solid, reliable function you can use in any front-end application:
function generateUUIDv4() { // Grab 16 random bytes const randomBytes = new Uint8Array(16); crypto.getRandomValues(randomBytes);
// Set the version to 4 randomBytes[6] = (randomBytes[6] & 0x0f) | 0x40;
// Set the variant to RFC 4122 randomBytes[8] = (randomBytes[8] & 0x3f) | 0x80;
// Convert the bytes to a hex string and add the hyphens const uuid = Array.from(randomBytes, byte => { return ('0' + byte.toString(16)).slice(-2); }).join('');
return ${uuid.slice(0, 8)}-${uuid.slice(8, 12)}-${uuid.slice(12, 16)}-${uuid.slice(16, 20)}-${uuid.slice(20)};
}
// How to use it: const newId = generateUUIDv4(); console.log(newId); // e.g., "1b9d6bcd-bbfd-4b2d-9b5d-ab8dfbbd4bed" This function is great because it manually sets the version and variant bits according to the RFC 4122 standard. This ensures any system expecting a proper V4 UUID will recognize it without issue.
On the Backend: Node.js Makes It Easy
Things get even simpler on the server with Node.js. Modern versions include a built-in crypto module that does all the heavy lifting for you.
To generate a secure V4 UUID, the randomUUID() method is all you'll ever need. It's a one-liner.
import { randomUUID } from 'node:crypto';
const userId = randomUUID(); console.log(userId); // e.g., "a1b2c3d4-e5f6-4a7b-8c9d-0e1f2a3b4c5d" That's it. This is my go-to for creating random IDs in any Node.js app. It's fast, secure, and best of all, requires zero external dependencies.
The security of your UUIDs is directly tied to the integrity of your entire application. Always leaning on battle-tested crypto libraries isn't just a good idea—it's a cornerstone of professional, robust system design. To explore this further, check out our guide on software development security best practices for more on building secure apps from the ground up.
Creating Deterministic V5 UUIDs in Node.js
What if you need an ID that's predictable and repeatable? As we covered earlier, that's exactly what Version 5 UUIDs are for—generating the same ID from the same inputs. While Node.js doesn't have a simple generateV5() function out of the box, building one with the crypto module's SHA-1 hashing capabilities is straightforward.
Here's the game plan:
- Pick a Namespace: This is just a starting UUID that gives your new IDs context. Generate one and reuse it.
- Hash Your Inputs: You'll combine the namespace with your unique name (like an email or URL) and run it through a SHA-1 hash.
- Format the Result: The final step is to tweak the hash bits to mark it as a proper V5 UUID.
Let's see what that looks like in practice:
import { createHash } from 'node:crypto';
function generateUUIDv5(namespace, name) { // Convert the namespace UUID string into bytes const namespaceBytes = Buffer.from(namespace.replace(/-/g, ''), 'hex');
// Create a SHA-1 hash of the namespace and name const hash = createHash('sha1'); hash.update(namespaceBytes); hash.update(name); const buffer = hash.digest();
// Set the version to 5 (0101) buffer[6] = (buffer[6] & 0x0f) | 0x50;
// Set the variant to RFC 4122 (10xx) buffer[8] = (buffer[8] & 0x3f) | 0x80;
// Format into the standard 8-4-4-4-12 string
const uuid = buffer.toString('hex', 0, 16);
return ${uuid.slice(0, 8)}-${uuid.slice(8, 12)}-${uuid.slice(12, 16)}-${uuid.slice(16, 20)}-${uuid.slice(20)};
}
// Example usage: const MY_NAMESPACE = 'f81d4fae-7dec-11d0-a765-00a0c91e6bf6'; const userEmail = '[email protected]'; const deterministicId = generateUUIDv5(MY_NAMESPACE, userEmail);
console.log(deterministicId); This gives you a powerful tool for creating stable, meaningful identifiers tied directly to your data. As you build out more complex systems, remember that tools are constantly improving; something like a code generation AI can help automate and secure these kinds of boilerplate implementations, letting you focus on the bigger picture.
Why an Offline UUID GUID Generator is a Smarter Choice
It might seem strange to argue for an offline tool when we do almost everything online. But when you’re generating identifiers for sensitive projects, using an online uuid guid generator opens the door to risks that many developers just don't think about. That quick web search for a generator can come with a hidden price tag on your privacy and security.
Every time you hit "generate" on a random website, you're trusting a third-party service. You have no idea if that server is logging your requests, tying your IP address to the UUIDs you just created, or what country's laws it even operates under. For a quick, throwaway ID, who cares? But what if that UUID is about to become a primary key for a new client's confidential database?
That's when local-first, offline tools stop being a simple preference and start becoming a professional necessity.
The Hidden Risks of Online Generators
The fundamental problem with online tools is the data transmission itself. Even if a site splashes "we respect your privacy" all over its homepage, the simple act of sending a request over the internet creates a record. This is a complete non-starter for anyone working in highly regulated fields.
Think about these real-world situations:
- Healthcare and Finance: Generating an ID for a patient record or a financial transaction on some unknown website could easily violate compliance standards like HIPAA or GDPR. These regulations have incredibly strict rules about where and how data is handled.
- Intellectual Property: If you're building a prototype for a new secret feature, even the metadata from your request could be logged. Now there's a digital breadcrumb trail leading back to your project that you have zero control over.
- Spotty Connections: What happens when your internet is flaky, or you're trying to get work done on a plane? An online tool is a dead end. An offline generator, on the other hand, just works. Instantly.
An offline generator elegantly dodges all these issues. Because the code runs entirely in your browser, no data ever leaves your machine. It’s a completely self-contained process, giving you absolute privacy and control.
Gaining Control with Client-Side Generation
A proper offline uuid guid generator taps into your browser's own built-in cryptographic functions—the same secure APIs we talked about for generating UUIDs with JavaScript. This means you're getting cryptographically strong, random identifiers without sending a single byte of data to an external server.
The advantages here are clear and immediate. You get zero network latency, so generation is instantaneous. Even better, it aligns perfectly with a modern, security-first mindset where you’re always looking to minimize external dependencies and shrink your application's attack surface.
Choosing an offline tool is really a strategic decision about data sovereignty. It’s about ensuring the creation of critical identifiers happens entirely within your trusted environment, which eliminates third-party risk completely.
This is exactly why so many professional development tools are built with an offline-first philosophy. They give you the utility you need without forcing a privacy trade-off. For anyone looking for a tool that lives by this principle, Digital ToolPad has a powerful, privacy-first UUID generator that runs 100% on your local machine.
Compliance and Peace of Mind
At the end of the day, it all boils down to risk management. An online tool might be fine for a personal blog or some non-critical data. But for any professional work where data integrity, security, and compliance actually matter, the choice is obvious.
An offline generator isn't just a handy utility; it's a key part of a secure development lifecycle. It makes certain that your identifier generation process is just as locked down as the rest of your codebase. By keeping this foundational step completely local, you wipe out an entire category of potential vulnerabilities and keep your work compliant, secure, and entirely under your control. It's just a smarter, safer way to build software.
Putting UUIDs to Work in Your Development Workflow
Generating a UUID is just the first step. The real art is knowing exactly where and how to use them in your applications to solve tricky problems. When you use them strategically, UUIDs can be a game-changer for data integrity and building resilient, distributed systems. But get it wrong, and you might introduce subtle performance bottlenecks that only show up when you're at scale.
So, let's look past the uuid guid generator and dive into the practical workflows where these identifiers really pull their weight, from database design all the way to API reliability.
UUIDs as Primary Keys: A Double-Edged Sword
One of the most heated debates you'll find among developers is whether to use UUIDs for primary keys in a database instead of a classic auto-incrementing integer. Honestly, there are strong arguments for both sides.
Why developers love UUIDs for keys:
- Decentralized Generation: You can create new, unique IDs anywhere—on a client device, in a serverless function, or on any microservice—without needing to ask the database first. This is a massive win for offline-first apps and distributed architectures.
- Better Security: Sequential IDs are a security risk. If a user can see
.../orders/101, they can probably guess that.../orders/102exists. A UUID like.../orders/f81d4fae-7dec...is impossible to guess, which helps protect your endpoints from snooping. - Easy Merging: Ever tried to merge two databases with conflicting integer keys? It's a nightmare. With UUIDs, collisions are statistically impossible, making data merges a breeze.
But here’s the performance catch:
Random V4 UUIDs can cause serious index fragmentation in databases that rely on clustered indexes (I'm looking at you, SQL Server). Because new records get inserted at random spots in the index rather than neatly at the end, write performance can really suffer over time.
This is exactly why there's so much buzz around the upcoming Version 7 UUIDs. They combine a timestamp with random bits, giving you the best of both worlds: a globally unique ID that's also sortable. This is much, much kinder to your database indexes.
API Idempotency Keys: Preventing Costly Duplicates
When you're building an API, especially for something critical like payment processing, you absolutely must prevent duplicate requests. Imagine a user's connection drops, so their app automatically retries a payment request. Without protection, you could end up charging them twice. This is where UUIDs are the perfect tool for idempotency.
The pattern is pretty straightforward:
- The client generates a fresh UUID and sends it along in a request header, like
Idempotency-Key: a1b2c3d4-.... - Your server gets the request and first checks a cache (like Redis) to see if it has ever seen that key before.
- If it’s a new key, the server processes the request and then saves the result in the cache with the key.
- If the key is already in the cache, the server skips the heavy lifting and just returns the saved result.
This simple workflow makes your API incredibly robust and saves you from the headaches caused by network glitches.
Correlation IDs for Microservice Tracing
In modern systems, a single user click can trigger a cascade of calls across a dozen different microservices. So when something breaks, how do you trace that one request's journey to find the root cause? The answer is correlation IDs.
The moment a request hits your API gateway, you generate a single UUID. This becomes the "correlation ID." From that point on, you pass this ID in the headers of every single internal API call made between your services.
When you ensure every log entry from every service includes this ID, you can use a tracing tool like Jaeger or Datadog to instantly pull up the complete, end-to-end story of that one request. It turns a painful debugging hunt into a simple, straightforward lookup.
The practical adoption of UUIDs and GUIDs is everywhere. Developers working in C#, Java, Python, JavaScript, Ruby, and C++ all have native functions for this built right into their standard libraries. For a deeper dive, you can learn more about GUID generation across different platforms on toolslick.com to see just how universal this technology is.
Storing UUIDs Efficiently
One last tip, and it’s a big one: store your UUIDs properly. A UUID is a 128-bit number, which is just 16 bytes. If you store it as a 36-character string (VARCHAR(36)), you're wasting more than double the space and slowing down every index lookup.
Don't do it. Nearly all modern databases, including PostgreSQL, MySQL, and SQL Server, have a native UUID or UNIQUEIDENTIFIER data type. Use it. It stores the ID in its compact 16-byte binary form, which is massively more efficient. This one small change can have a huge impact on your database performance and size as you scale.
Common Questions About UUIDs and GUIDs
As you start working with UUIDs, you'll inevitably run into a few common questions. Let's clear up some of the most frequent points of confusion so you can use these identifiers with confidence.
What's the Real Difference Between a UUID and a GUID?
Honestly, for just about any modern development work, there’s no functional difference. The two terms are used interchangeably.
UUID stands for Universally Unique Identifier. It’s the formal name for the standard defined by the IETF in RFC 4122. GUID, or Globally Unique Identifier, is simply what Microsoft called their implementation of the same idea. While there were some minor byte-ordering quirks in very old Microsoft systems, that's almost never a concern today.
So, if you're in a .NET environment and generate a GUID, you're getting a standard 128-bit UUID. Simple as that.
Could a UUID V4 Ever Actually Create a Duplicate?
Theoretically? Yes. Realistically? No. It's so statistically improbable that you can safely consider it impossible.
A Version 4 UUID has 122 bits of pure randomness. This gives us a mind-boggling 5.3 undecillion (that's 5.3 x 10^36) possible combinations. The odds of a collision are so vanishingly small they just don't factor into real-world application design.
To give you a sense of scale, you would need to generate one billion UUIDs every single second for about 85 years just to reach a 50% chance of a single collision. For all practical purposes, the probability is zero. You have a far greater chance of your server being hit by a meteor.
When Would I Use a Name-Based UUID Instead of a Random One?
You reach for a name-based UUID (like Version 5, which uses SHA-1) when you need a consistent and repeatable identifier from a given input. It's all about determinism: same input, same UUID, every single time.
This is perfect for scenarios like:
- Creating a stable user ID from an unchanging email address.
- Generating a unique identifier for a web resource based on its URL.
- Producing a consistent ID for a configuration setting derived from its name and value.
But if you just need a unique ID for a new database record, a transaction, or a log entry, a randomly generated Version 4 is the way to go. Its unpredictability is a key feature for ensuring uniqueness without dependencies.
Are There Performance Downsides to Using UUIDs as Primary Keys?
Yes, this is something you absolutely need to be aware of, especially with databases.
First, UUIDs are bigger than traditional auto-incrementing integers (16 bytes vs. 4 or 8 bytes). This means more storage space and larger, potentially slower indexes. The bigger issue, though, is index fragmentation.
Because random UUIDs (like V4) have no natural order, new records get inserted at random spots within the database index. This is a lot more work for the database than simply appending a new, sequential number to the end. This can really slow down write performance, particularly with clustered indexes.
Some databases have special UUID data types to help with this, but it’s a well-known tradeoff. This performance challenge is also what’s driving the creation of newer, sortable UUIDs like the upcoming Version 7, which cleverly combines a timestamp with random data to get the best of both worlds.
Still have questions or just need a reliable tool? The Digital ToolPad suite includes a powerful, privacy-first uuid guid generator that runs 100% offline in your browser. Get instant, secure UUIDs without sending any data to a server. Try it now at https://www.digitaltoolpad.com.